 | |
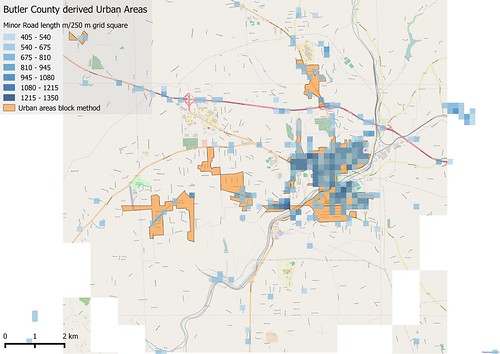
| Comparison of Urban Areas derived using "block method" and gridded road density. Only grid squares with over 500 m of road included. The area shown is around Butler, Butler Co, PA |
Again I've used Butler County data from OpenSteetMap. I created a 250 m square grid in the (Google) Spherical Mercator projection, and simply summed up the road lengths in each grid square (roads were coerced to a geography type in PostGIS). Visual inspection of binned data suggested a value of between 400 and 500 metres/square gave reasonably discrete areas, and reduced artefacts along major roads. I show the result obtained above compared with the "block method" described in the previous post.
An alternative way is to apply a finer grid of lines not polygons and split these grid lines each time they are intersected by a road. I've also done this for Butler County, although PostGIS doesn't provide any simple way to split a single line into multiple parts based on intersections.
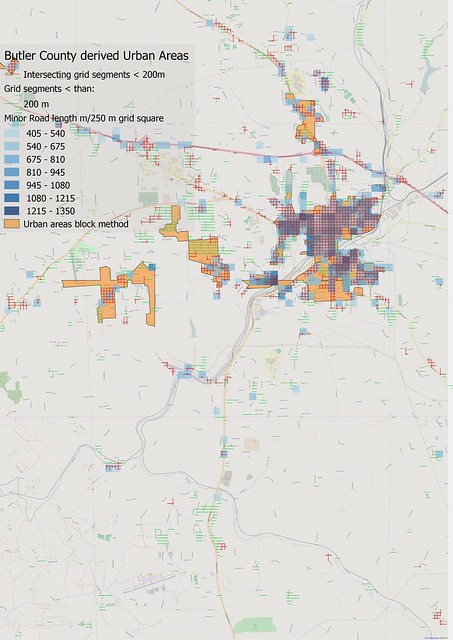 |
| Urban Area derivation, with results of grid intersection methods superimposed on gridded road density and block method results Area around Butler, Butler Co, PA |
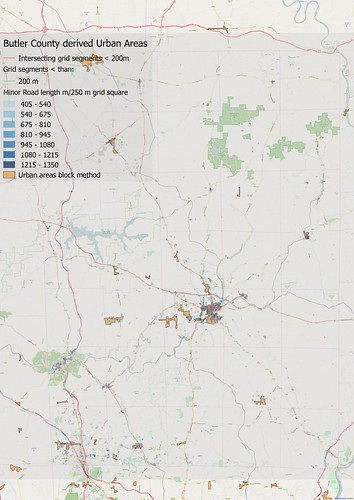 |
| As above, Butler County as a whole. |
The two road density methods described here produce somewhat smaller polygons than the block method, but seem to be better than the latter for picking up smaller residential areas which tend to get eliminated in the latter method. Both methods may suffer for larger areas as the size of such closely spaced grids is likely to have adverse effects on performance.
I think this concludes discussion of urban area derivation techniques applicable for complete road networks with unclear or inaccurate attribution, such as US Tiger data.
Appendix: Cutting a line at each intersection in PostGIS
One is so used to the power and flexibility of modern FOSS GIS tools, notably those from OSGeo, that it comes as a shock when what seems like a common operation is not supported directly. The OSM desktop editor JOSM, for instance provides a tool to split a way into multiple fragments.I'd hoped to split each x & y grid line at each point when it was crossed by a road. Filtering for only small segments would identify when roads were more frequent. The problems associated with doing this in PostGIS are reasonably well described here on GIS StackOverflow. The second answer looks interesting but provides no guidance, and ST_NODE must remain a mystery as there is no clear explanation of the magic it works, other than it replaces another bit of magic using ST_UNION.
So I did something quick & dirty. I found all the intersection points between the grid lines & the road nework, taking care to retain the grid line identifiers. I then constructed lines from any intersection point to points either further east or north (using << and <<| operators) located on the same line & selected the shortest one. I then filtered to get those shorter than 200 m. In practice if I had known I was going to use 200 m as my filter I could have thrown out all the longer lines at that stage.
No comments:
Post a Comment
Sorry, as Google seem unable to filter obvious spam I now have to moderate comments. Please be patient.